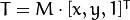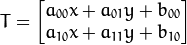前言
图割算法主要有两个发展方向,一个是 Shaun 上次写过的 Graph Cuts ,通过边界项和区域项(有的可能还会添加一个约束项,或者叫标签项)之和建立能量方程,并利用一定程度的交互式构建一个 S/T 图,最后采用最大流/最小割(Max-flow/Min-cut )算法寻找 S/T 图的最小“割”,从而对图像进行分割;而另一个方向就是 NCuts(Normalized Cuts),中文一般叫规范割、标准割等等,该方法主要出自:Shi J, Malik J. Normalized cuts and image segmentation[J]. IEEE Transactions on pattern analysis and machine intelligence, 2000, 22(8): 888-905. 。
前言
图割算法主要有两个发展方向,一个是 Shaun 上次写过的 Graph Cuts ,通过边界项和区域项(有的可能还会添加一个约束项,或者叫标签项)之和建立能量方程,并利用一定程度的交互式构建一个 S/T 图,最后采用最大流/最小割(Max-flow/Min-cut )算法寻找 S/T 图的最小“割”,从而对图像进行分割;而另一个方向就是 NCuts(Normalized Cuts),中文一般叫规范割、标准割等等,该方法主要出自:Shi J, Malik J. Normalized cuts and image segmentation[J]. IEEE Transactions on pattern analysis and machine intelligence, 2000, 22(8): 888-905. 。
提到 NCuts,就不得不提「谱聚类」,因为 NCuts 可以说是谱聚类的一个应用。
谱聚类篇
谱聚类(Spectral Clustering, SC)是一种基于图论的聚类方法——将无向带权图划分为两个或两个以上的最优子图(sub-Graph),使子图内部尽量相似,而子图间距离尽量远,以达到常见的聚类的目的。
在了解谱聚类之前需要先了解两个概念:拉普拉斯矩阵(Laplace Matrix)和瑞利熵(Rayleigh quotient)。
拉普拉斯矩阵
拉普拉斯矩阵的定义如下:
设 \(W\) 为无向带权图 \(G=(V,E)\) 的邻接矩阵,\(D\) 为无向带权图 \(G\) 的度矩阵,(所谓的度矩阵即为图中各顶点邻接的所有边权值之和构成的矩阵,是一个对角矩阵,若设顶点 \(i\) 和顶点 \(j\) 之间的权值为 \(w(i,j)\),则度矩阵对角线上的元素 \(d_{i,i}=\sum \limits_{j=1}^n w(i,j)\) ),则拉普拉斯矩阵 \(L=D-W\)。如下图:
若图的邻接矩阵:\(\mathbf{W}=\begin{pmatrix} 0 & 0.1 & 0 & 0 & 0.2 & 0 \\ 0.1 & 0 & 0 & 0.5 & 0.1 & 0 \\ 0 & 0 & 0 & 0.3 & 0 & 0.4 \\ 0 & 0.5 & 0.3 & 0 & 0 & 0.1 \\ 0.2 & 0.1 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0.4 & 0.1 & 0 & 0 \end{pmatrix}\) ,其中图中不连通的顶点之间的权值为 0;
则对应的度矩阵为:\(\mathbf{D}=\begin{pmatrix} 0.3 & 0 & 0 & 0 & 0 & 0 \\ 0 & 0.7 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0.7 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0.9 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0.3 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0.5 \end{pmatrix}\)
则拉普拉斯矩阵 \(L\) 为:\(\mathbf{L}=\mathbf{D}-\mathbf{W}=\begin{pmatrix} 0.3 & -0.1 & 0 & 0 & -0.2 & 0 \\ -0.1 & 0.7 & 0 & -0.5 & -0.1 & 0 \\ 0 & 0 & 0.7 & -0.3 & 0 & -0.4 \\ 0 & -0.5 & -0.3 & 0.9 & 0 & -0.1 \\ -0.2 & -0.1 & 0 & 0 & 0.3 & 0 \\ 0 & 0 & -0.4 & -0.1 & 0 & 0.5 \end{pmatrix}\)
以上三个矩阵都为实对称矩阵。对于拉普拉斯矩阵,由 $L* [1,1,1,1,1,1]^T =0* [1,1,1,1,1,1]^T= $ 可知其一定存在一个特征值为 0,对应的特征向量为 \([1,1,1,1,1,1]^T\) 。
拉普拉斯矩阵是半正定的,且对应的 n 个实数特征值都大于等于 0,即 \(0=λ_1≤λ_2≤\cdots≤λ_n\), 且最小的特征值为 0 。
至于拉普拉斯矩阵的更多性质,可参考:Laplacian matrix 。
瑞利熵
瑞利熵的公式形如:\(R(M,x)=\frac{x^*Mx}{x^*x}\) ,其中 M 是厄米特矩阵(Hermitian matrix),满足 \(M=M^H\) ,即矩阵 \(M\) 与其共轭转置矩阵相等,\(x\) 为非 0 向量,\(x^*\) 是指 \(x\) 向量的共轭转置向量。对于实数而言,厄米特矩阵就是对称阵 \(M=M^T\),\(x^*\) 就是 \(x\) 向量的转置向量 \(x'\) 或 \(x^T\)。
若设 \(x^*x=c\),其中 \(c\) 为一个常数,则 \(R(M,x)=\frac{x^*Mx}{c}\) ,则其极值问题可转化为:\(\min R(M,x) = \min x^*Mx \qquad s.t.\ x^*x=c\) ,可利用拉格朗日乘数法求取 \(x^*Mx\) 的极值。 具体求法如下: \[ \mathcal{L}(x) = x^T M x -\lambda \left (x^Tx - c \right) \\ \begin{align} &\frac{d\mathcal{L}(x)}{dx} = 0 \\ &\Rightarrow x^TM - \lambda x^T = 0 \\ &\Rightarrow Mx - \lambda x = 0 \\ &\Rightarrow M x = \lambda x \end{align} \\ \therefore R(M,x) = \frac{x^T M x}{x^T x} = \lambda \frac{x^Tx}{x^T x} = \lambda. \]
瑞利熵有如下几个性质:
- R 的最大值就是 M 最大特征值,R 的最小值就是 M 最小特征值 ;
- x 的解,就是 M 对应的特征向量。
至于瑞利熵的更多性质,可参考:Rayleigh quotient 。
以上只是一般意义上的普通瑞利熵,还有一个广义瑞利熵(generalized Rayleigh quotient ),其定义为:\(R(M,D;x)=\frac{x^*Mx}{x^*Dx}\) ,即在分母上添加一个 D 矩阵相乘,其中 D 为 Hermite 正定矩阵 ,满足 \(D=D^*\),普通瑞利熵是广义瑞利熵中 D 矩阵为单位矩阵时的情况。广义瑞利熵可以通过以下变换转换为普通瑞利熵: \[ \begin{equation} \begin{aligned} R(M,D;x) &= \frac{x^*Mx}{x^*Dx} \xlongequal{x=D^{-\frac{1}{2}}y} \frac{(D^{-\frac{1}{2}}y)^*M(D^{-\frac{1}{2}}y)}{(D^{-\frac{1}{2}}y)^*D(D^{-\frac{1}{2}}y)} \\ &= \frac{y^*(D^{-\frac{1}{2}})^*M(D^{-\frac{1}{2}}y)}{y^*(D^{-\frac{1}{2}})^*D(D^{-\frac{1}{2}}y)}=\frac{y^*D^{-\frac{1}{2}}MD^{-\frac{1}{2}}y}{y^*D^{-\frac{1}{2}}DD^{-\frac{1}{2}}y} \\ &= \frac{y^*(D^{-\frac{1}{2}}MD^{-\frac{1}{2}})y}{y^*y} \end{aligned} \end{equation} \]
只需要求出矩阵 \(D^{-\frac{1}{2}}MD^{-\frac{1}{2}}\) 的特征值和特征向量即可。
好了,这两个概念介绍完了,就可以真正介绍谱聚类了。
上面说了,谱聚类是一种基于图论的聚类方法,既然有图,则必有相应的邻接矩阵。设图 G 的顶点被聚类成两类,即将图 G 分割为子图 A 和 B,则所要断开的边的权值之和为代价函数(也叫损失函数),类似于“Graph Cuts”中的能量方程。割边 Cut(A,B) 的具体表示为:\(Cut(A,B)=\sum \limits_{i \in A,j \in B} w(i,j)\) 。
设图 \(G\) 中共有 \(n\) 个顶点,则需要构建一个 \(n \times n\) 的邻接矩阵 \(W\),其相应的度矩阵为 \(D\),对应的拉普拉斯矩阵为 \(L=D-W\),令 \(p_i = \begin{cases} l_1 & i \in A \\ l_2 & i \in B\end{cases}\) ,则 \[ Cut(A,B)=\sum \limits_{i \in A,j \in B} w(i,j) = \frac{\sum \limits_{i=1}^n \sum \limits_{j=i}^n w(i,j) (p_i-p_j)^2}{(l_1-l_2)^2}= \frac{\sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (p_i-p_j)^2}{2(l_1-l_2)^2} \]
当且仅当 \(i\) 和 \(j\) 不属于同一子图时,\((p_i-p_j)^2/(l_1-l_2)^2=1\),否则 \((p_i-p_j)^2/(l_1-l_2)^2=0\),(为什么采取这种计算方式,是因为在无法直接确定割边时,用这种计算方式能确保全部割边且只有割边会被加入权重之和),至于为什么等式最后还要除以 2 ,是因为等式最后的那种写法每条边会被遍历两次,每条割边权值会被计入两次,所以还要除以2。
而: \[ \begin{equation} \begin{aligned} & \sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (p_i-p_j)^2 = \sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (p_i^2-2p_ip_j+p_j^2) \\ &= \sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (p_i^2) + \sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (p_j^2) - \sum \limits_{i=1}^n \sum \limits_{j=1}^n w(i,j) (2p_ip_j) \\ &= \sum \limits_{i=1}^n p_i^2 (\sum \limits_{j=1}^n w(i,j)) + \sum \limits_{j=1}^n p_j^2 (\sum \limits_{i=1}^n w(i,j)) - 2\sum \limits_{i=1}^n \sum \limits_{j=1}^n p_iw(i,j) p_j \\ &= p^TDp+p^TDp-2p^TWp = 2p^T(D-W)p = 2p^TLp \end{aligned} \end{equation} \]
则:\(Cut(A,B)=\frac{p^TLp}{(l_1-l_2)^2}\) ,当 \(l_1=1,l_2=-1\) 时, \(\min Cut(A,B) = \min p^TLp \qquad s.t.\ p^Tp=n\) ,n 为图的顶点个数。由上可知,该最小割问题即是一个瑞利熵问题,只需求取 \(L\) 的特征值和特征向量。
对 \(L\) 的特征值进行从小到大排列(即取最小 k 个特征向量),若要分成 k 类,则需要取前 k 个特征值(除 0 以外)对应的特征向量,并归一化,将每一个特征向量按列排列构成一个 \(n \times k\) 的特征矩阵,对特征矩阵的行向量使用 k-means 或其它聚类算法,将 n 个行向量聚成 k 类,每一行都属于某一类,根据聚类结果为每个顶点分配相应的类标签,从而完成谱聚类。所以利用谱聚类求的解相当于是一个近似解,它将连续的 n 维问题离散化为 k 维问题,p 是一个 n 维的标签向量,标签值为 \(\{1,2,\cdots,k\}\) ,而 \(L\) 的特征向量中的元素并不是离散化的 \(\{1,2,\cdots,k\}\) ,无法直接用 \(L\) 的特征向量作为标签向量,所以需要将其离散化,对特征矩阵的行向量进行聚类,从而近似的生成标签向量;由于只取前 k 个特征向量,所以在对特征矩阵进行聚类时被聚类的 n 条数据只有 k 维,而本来 \(L\) 的特征向量至少有 n 个,即被聚类的 n 条数据至少有 n 维,所以从某种程度上,谱聚类同时也对数据进行了降维处理。
※注: 推荐使用 SVD 代替特征值和特征向量的求取。至于谱聚类的更多性质,可参考:Spectral clustering。
因为有时候简单的全局最小割,可能并不是最优割,所以需要对割做一个归一化,即 Normalized Cuts ,简称 NCuts。
图篇
同样,Shaun 还从图的构造开始,NCuts 所需要构造的图就是最普通的无向带权图,图的顶点由图像中像素点构成,相邻的像素点之间互相连接构成图的边。边的权值计算公式为: \[ w(i,j) = e^{\dfrac{-\|\mathbf{F}(i)-\mathbf{F}(j)\|_2^2}{\sigma_I}} * \begin{cases} e^{\dfrac{-\|\mathbf{X}(i)-\mathbf{X}(j)\|_2^2}{\sigma_X}} & \text{if } \|\mathbf{X}(i)-\mathbf{X}(j)\|_2 < r \\ 0 & \text{otherwise}. \end{cases} \] 其中 \(\mathbf{X}(·)\) 是指该顶点的空间位置向量,即图像中像素点的坐标; \(\mathbf{F}(·)\) 可指像素点的强度(灰度)值,颜色向量或纹理值;\(\|\mathbf{X}(i)-\mathbf{X}(j)\|_2\) 表示向量的「2-范数」,即欧氏距离。当 \(\mathbf{F}(·)\) 表示强度(灰度)值时,NCuts 分割的是灰度图;当 \(\mathbf{F}(·)\) 表示颜色向量(一般在 HSV 颜色空间,有 \((h,s,v)\) 三个颜色分量)时,NCuts 分割的是彩色图。对于这个权值的计算说人话就是:当两个像素点之间的距离大于一个人为指定的 \(r\) 时(其实也就用这个 \(r\) 判断到底是连接 4 邻域还是连接 8 邻域,一般不会连接 8 邻域之外的像素点),就不连接,此时权值设为 0 ;否则,则计算两像素点颜色向量的 RBF 核的值和两像素点坐标向量的 RBF 核的值,并取其乘积作为权值。
好了,Ncuts 的图的构成大致就是这样。接下来就是它的割法了。
割篇
NCuts 中定义割 \(Cut(A,B)=\sum \limits_{i \in A,j \in B} w(i,j)\) ,定义 \(assoc(A,V)=\sum\limits_{i \in A,t \in V}w(i,t)\) 为子图 A 内所有像素点连接的所有边权重之和,最终的 NCuts 目标函数如下: \[ Ncut(A,B)= \frac{cut(A,B)}{assoc(A,V)}+\frac{cut(A,B)}{assoc(B,V)} \] 即通过除以两个子图内所有像素点连接的所有边权值之和对割做了个归一化处理。
令 \(\mathbf{W}\) 为图的邻接矩阵, \(\mathbf{D}\) 为其对应的度矩阵,\(L=D-W\) 为其对应的拉普拉斯矩阵,令 \(S_1 = assoc(A,V) = \sum\limits_{i \in A}D_{ii}\),\(S_2 = assoc(B,V) = \sum\limits_{i \in B}D_{ii}\),则 \(S = S_1+S_2=\sum\limits_{i \in A}D_{ii}+\sum\limits_{i \in B}D_{ii}=\sum D_{ii}= \sum \limits_{i=1}^n\sum \limits_{j=1}^n w(i,j)\) ,则:\(NCut(A,B)=\frac{p^TLp}{(l_1-l_2)^2}*(\frac{1}{S_1}+\frac{1}{S_2})\) ,其中向量 \(p\) 为 \(N=|V|\) 维的标签向量, \(p_i = \begin{cases} l_1 & i \in A \\ l_2 & i \in B\end{cases}\) ,令 \(l_1 = \sqrt{\frac{S_2}{S_1S}},l_2=-\sqrt{\frac{S_1}{S_2S}}\) ,则 \(NCut(A,B)=p^TLp\) ,此时 \(p^TDp=\sum p_i^2D_{ii}=\sum\limits_{i \in A}l_1^2D_{ii}+\sum\limits_{i \in B}l_2^2D_{ii}=l_1^2S_1+l_2^2S_2=1\) ,则可化为 \(NCut(A,B)=\frac{p^TLp}{p^TDp}\) ,即 \(\min NCut(A,B) = \min p^TLp \qquad s.t.\ p^TDp=1\) ,该式即为一个广义瑞利熵,只需要求出矩阵 \(D^{-\frac{1}{2}}LD^{-\frac{1}{2}}\) 的特征值和特征向量,按照谱聚类最后的聚类方式将顶点(像素点)聚成 k 类,从而完成图像的分割。而 NCuts 有个特殊的变换,具体如下: \[ \begin{equation} \begin{aligned} NCut(A,B) &=\frac{p^TLp}{p^TDp}\xlongequal{p=D^{-\frac{1}{2}}x} \frac{x^T(D^{-\frac{1}{2}}LD^{-\frac{1}{2}})x}{x^Tx} \\ &= \frac{x^T(D^{-\frac{1}{2}}(D-W)D^{-\frac{1}{2}})x}{x^Tx} \\ &= \frac{x^T(D^{-\frac{1}{2}}DD^{-\frac{1}{2}})x}{x^Tx} - \frac{x^T(D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x}{x^Tx} \\ &= I - \frac{x^T(D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x}{x^Tx} \end{aligned} \end{equation} \] 使用该变换可得出:\(\min NCut(A,B) = \max x^T(D^{-\frac{1}{2}}WD^{-\frac{1}{2}})x \qquad s.t.\ x^Tx=1\) ,这样可不求出拉普拉斯矩阵,直接求出 \(D^{-\frac{1}{2}}WD^{-\frac{1}{2}}\) 的特征值和特征矩阵即可,而此时在谱聚类最后聚类的时候要将其特征值从大到小排列(即取最大 k 个特征向量),取前 k 个特征值对应的特征向量构造特征矩阵进行聚类。
附录
Ratio Cuts(RCuts) 和 NCuts 的目标函数差不多,两者间的差异就是:RCuts 是除以子图内顶点的个数;NCuts 是除以子图内所有顶点的边权值之和;最后变换完之后 RCuts 是个普通瑞利熵,而 NCuts 是个广义瑞利熵。具体的 RCuts 割法等以后有机会用到再写吧,毕竟子图顶点个数多不代表所占权重就大,而且在割时一般是基于权重的,所以一般而言 NCuts 的结果要比 RCuts 的结果要好。
总结
由上文中应该可以看出 NCuts 与 Graph Cuts 需要构造的图是不一样,所使用的能量方程从形式上看也是完全不一样的(虽然本质上都是求“最小割”),其构成的图主要差别在于 Graph Cuts 多了 S 和 T 两个顶点,而这两个顶点由交互式获取,NCuts 不需要交互式,因此也没有这两个顶点,Ncuts 构造的图就相当于只由 Graph Cuts 的普通顶点和边界项 n-links 构成图,因此 Ncuts 没有 Graph Cuts 所谓的区域项 t-links ,也不需要求区域项 t-links 的权值。而这两种方法边界项 n-links 的权值求法都是差不多的,都是用 (高斯)RBF 核函数进行相似性度量,即 \(w_{\{i,j\}} \propto exp\left(-\frac{(I_i-I_j)^2}{2\sigma^2}\right)\) 。
后记
后面查阅资料发现图割其实还有好几个方向(井底之蛙了o(╯□╰)o),等有机会把用图割做超像素分割的那篇论文看一下吧 😜 。
5 月份的时候自己抽空实现了一下该算法,发现效果很糟糕,分割效果很不理想,当然不排除 Shaun 代码有 BUG 的原因,或者是还有一些步骤或 trick 漏掉了 ╮(╯▽╰)╭。而且不管是用 svds 还是 eigs 其分割结果都是随机的,只能保证邻域内像素点大概在一起,但具体谁和谁在一起这就是随机的了,这导致每次运行程序都可能有不同的分割结果 _(´ཀ`」 ∠)_ ,后面发现分割结果随机应该是 k-means 的锅(与 svd 和 eig 无关),原因是因为 k-means 每次初始化 k 个种子点时都是随机的,这自然会导致每次分割结果不完全一致 o(╯□╰)o。
参考资料
[1] 【聚类算法】谱聚类(Spectral Clustering)
[2] 谱聚类算法(Spectral Clustering)
[3] 拉普拉斯矩阵(Laplace Matrix)与瑞利熵(Rayleigh quotient)(http://www.cnblogs.com/xingshansi/category/958994.html)
[4] Normalized cuts and image segmentation 简单实现
[5] 谱聚类(spectral clustering)原理总结 (http://www.cnblogs.com/pinard/category/894692.html)

 矩阵来表示仿射变换.
矩阵来表示仿射变换.
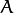 和
和 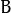 对二维向量
对二维向量 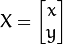 做变换, 所以也能表示为下列形式:
做变换, 所以也能表示为下列形式: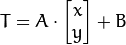 or
or