前言
这是一篇译文,译自:Why Deep Learning Has Not Superseded Traditional Computer Vision,原作者为:Zbigatron 。Shaun 水平有限,仅供参考学习,更多内容还请自行查看原文。
至于为什么要翻译这篇文章,算是回答别人的一个问题吧。
为什么深度学习还没有取代传统的计算机视觉?
编写这篇文章的原因是在论坛中经常有人问:深度学习是否取代了传统的计算机视觉?或者类似的问题:深度学习效果这么好,还有继续研究传统计算机视觉的必要?
这是个好问题,深度学习(DL)确实彻底改变了计算机视觉(CV)和人工智能,许多曾经看起来不可能解决的问题都解决了,甚至达到了 机器的结果比人类更好 的程度,比如图像分类。正如 我之前讨论的,深度学习确实为计算机视觉做了很大的贡献。
但是深度学习只是计算机视觉的一个工具,并不是解决所有问题的万能药,所以,在这篇文章中,我想详细说明一下为什么传统的计算机视觉仍然非常有用,并且应该继续学习。
这篇文章主要有一下几个观点:
- 深度学习需要大量数据;
- 深度学习有时大材小用了;
- 传统的计算机视觉可以辅助深度学习。
但是在我开始讨论这些观点之前,需要先解释一下什么是传统的计算机视觉,什么是深度学习,以及深度学习为何这么 dio。
背景知识
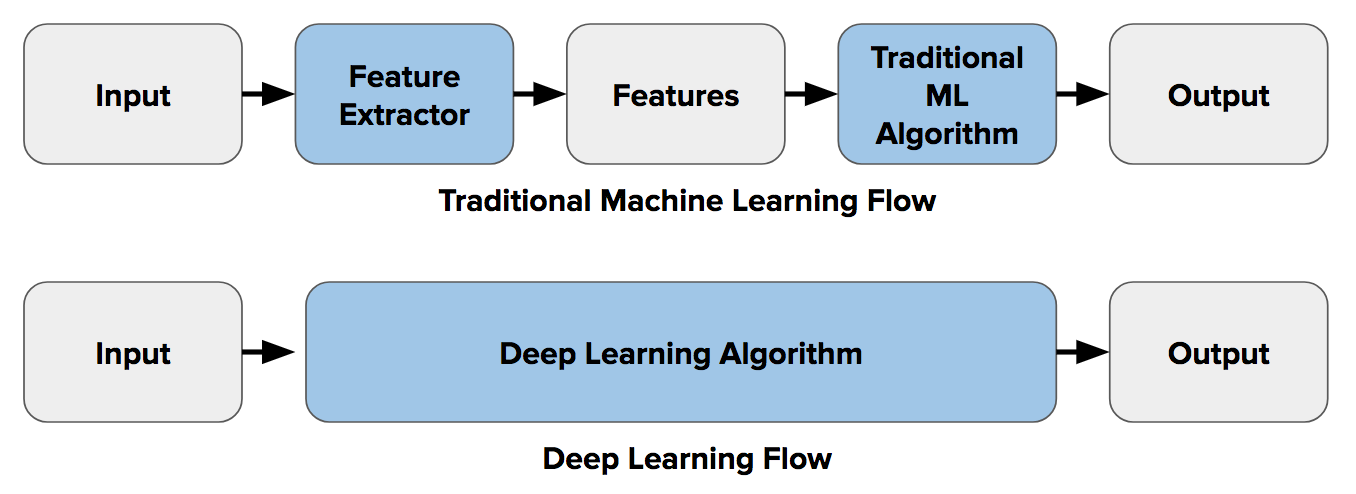
在深度学习之前,如果要实现图像分类这样的功能,需要首先进行 特征提取。特征即为图像中的信息块,能代表图像的部分信息,可以通过 边缘检测,角点检测,物体检测 等技术来提取特征。
在进行特征提取和图像分类之类的工作时,一个想法是从一类对象(例如椅子,马等)的图像中提取尽可能多的特征,并将这些特征视为对象的一种定义(比如 词袋模型),然后在其他图像中查找这些定义,若另一个图像中的特征和定义的特征很相似,则该图像可能包含该特定的对象(如椅子,马等)。
在图像分类中,这种特征提取的难点在于每个图像都必须选择哪些特征进行查找,当需要分类的类别开始增加时,比如 10 或 20 种类别,这种方式将变得很麻烦以至于不可能实现。当然也可以考虑角点、边缘和纹理信息,使用不同的特征可以更好的描述不同类别的对象,但是如果选择使用很多特征,则必须处理大量参数,所有这些参数都必须微调。
深度学习中有一个端到端学习的概念,其含义为告诉机器要针对每个特定类别对象学习需要查找的特征,它为每个对象设计了最具描述性和显著性的特征,换言之,告诉神经网络要发现图像中每个类别的基本模式。
因此,通过端到端学习,不需要再决定使用哪种传统的计算机视觉技术来描述特征,机器自动选择好了,Wired magazine 说过:
如果想教一个神经网络识别一只猫,不需要让它寻找胡须、耳朵、皮毛和眼睛,只需要给它大量猫的图像,它就会自动识别猫,若它将狐狸错认成猫,不需要重写代码,只需要继续训练即可。
下图表示了特征提取(使用传统计算机视觉)和端到端学习之间的差异:
以上就是需要的背景知识,下面开始深入探讨为什么传统的计算机视觉仍然有存在的必要。
深度学习需要大量数据
首先,深度学习需要大量的数据,那些著名的图像分类模型就是在海量数据集上训练的,训练数据集中最大的三个是:
- ImageNet – 150 万张图片,包含有 1000 个对象类别;
- Microsoft Common Objects in Context (COCO) – 250 万张图片,91 个对象类别;
- PASCAL VOC Dataset – 50 万张图片,20 个对象类别。
一般的图像分类任务不需要这么多图片,但仍然需要很多,如果没办法获得这么多图片怎么办?我们还是得训练我们所有的数据(有些方法可以增多我们的训练数据,但这些都是人工方法)。但是,没有足够的数据支持,训练出来的模型可能会在训练集之外表现不好,因为机器没有洞察能力,无法对没有的数据进行分类。而且无法直观查看训练好的模型并手动调整里面的数据,因为深度学习模型里面有数百万个参数,并且这些参数在训练时会自动微调,某种程度上,深度学习模型就是一个黑盒子。
传统的计算机视觉完全透明,可以很清楚的判断自己的解决方案在训练数据之外是否可行,而且可以深入了解算法中存在的问题。如果有没法解决的问题,也可以更容易的找出原因并调整。
深度学习有时大材小用了
这可能是我支持传统计算机视觉技术研究的最佳理由。
训练深度神经网络需要很长时间,而且需要专门的硬件(高性能 GPU),如果想在普通的笔记本上训练最先进的图像分类模型,可以去外面玩一个星期,回来之后应该还没训练完 :) 。而且,如果训练好的模型表现不好怎么办?必须调整训练参数并重新开始训练,这个过程有时会重复数百次。
但有时候使用深度学习是完全没有必要的,因为有时传统的计算机视觉技术可以比深度学习更有效的解决问题并且代码更少。比如,我曾经做过一个项目来检测传送带上每个罐头是否都有红色的勺子,解决这个问题可以训练深度神经网络来检测勺子,也可以针对红色编写一个简单的阈值分割算法(红色的某个范围内的像素点为白色,其它像素点为黑色),然后计算有多少个白色像素点,后者明显简单的多,一个小时就完成了。
了解传统的计算机视觉有时会节省大量时间和避免不必要的麻烦。
传统计算机视觉提高改进深度学习技能
了解传统的计算机视觉可以帮助我们更好地进行深度学习。
例如,计算机视觉中使用的最常见的神经网络是卷积神经网络。但什么是卷积?它实际上是一种广泛使用的图像处理技术(例如 Sobel边缘检测)。了解这一点可以帮助我们了解神经网络正在做什么,并因此可以更好的设计和调整神经网络来解决问题。
深度学习中还可以对图像进行预处理,所谓的预处理是指对训练的数据进行一定的处理(Shaun 注:比如图像增强,图像去噪等),这些预处理操作一般由传统的计算机视觉技术完成,比如:当没有足够的训练数据时,可以使用一种叫数据增强的技术,使用数据增强让图像进行旋转,平移,裁剪等操作,从而增加“新”图像,通过执行这些操作,可以成倍的增加训练数据集。
总结
在这篇文章中,我解释了为什么深度学习还没有取代传统的计算机视觉技术,因此还需要研究后者。首先我发现了深度学习要想表现的足够好需要大量数据的问题,有时候没法获得大量数据,这时只能用传统计算机视觉技术代替;其次,对于特定的任务,使用深度学习可能大材小用了,传统计算机视觉有时比深度学习更有效且代码量也更少;最后了解传统的计算机视觉可以更好的学习深度学习,因为这可以使我们更好的了解深度学习的内部机制,并且可以使用某些预处理操作来改善深度学习结果。
简而言之,深度学习只是计算机视觉的一个工具,不是万能药,不要只是因为它现在很流行所以使用它,传统的计算机视觉技术仍然十分有用,了解它可以节省时间和避免许多麻烦。
后记
翻译这篇文章的原因在于,因为某些原因,Shaun 不得不回答一个 “为什么不用深度学习?” 的问题,虽然这里面有极大的因素是客观原因(设备不够 ╮(╯▽╰)╭),但 Shaun 不能明说,正好在网上看到这篇文章,加上也看到过一个问题(类似于 “既然已经能用深度学习做高层次的工作,为何还要用深度学习做底层的工作?”,比如深度学习能做全景分割(可以说是基本完成了图像理解),为何还要做目标检测,图像分割),预计以后有很大的概率也会被问到,所以就需要借用文中的一些观点来进行回答。至于为啥还要用深度学习做底层的工作,可以这样认为,如果用深度学习做底层工作效果不错的话,应该可以对上层工作进行一些辅助,并且可以为上层工作的做法提供一些新的思路。