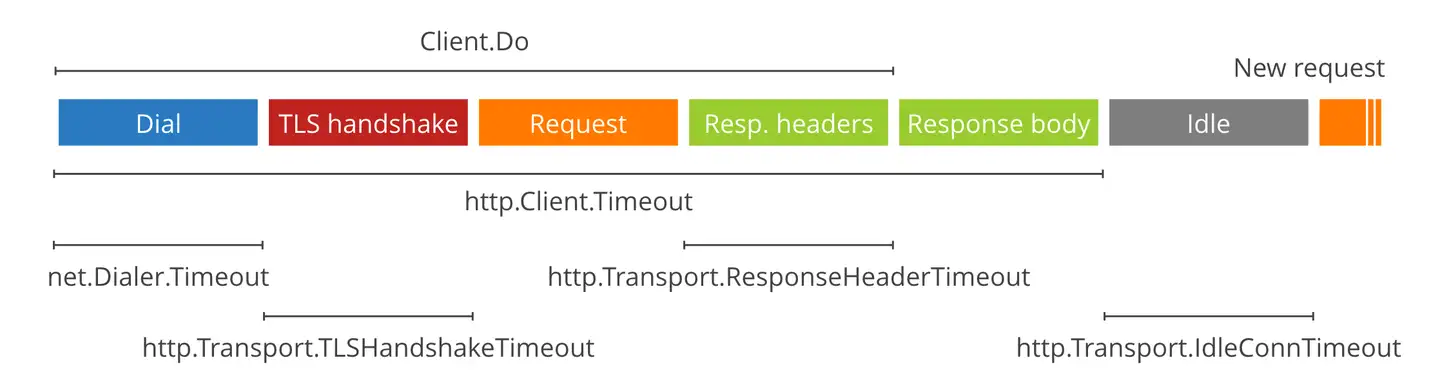
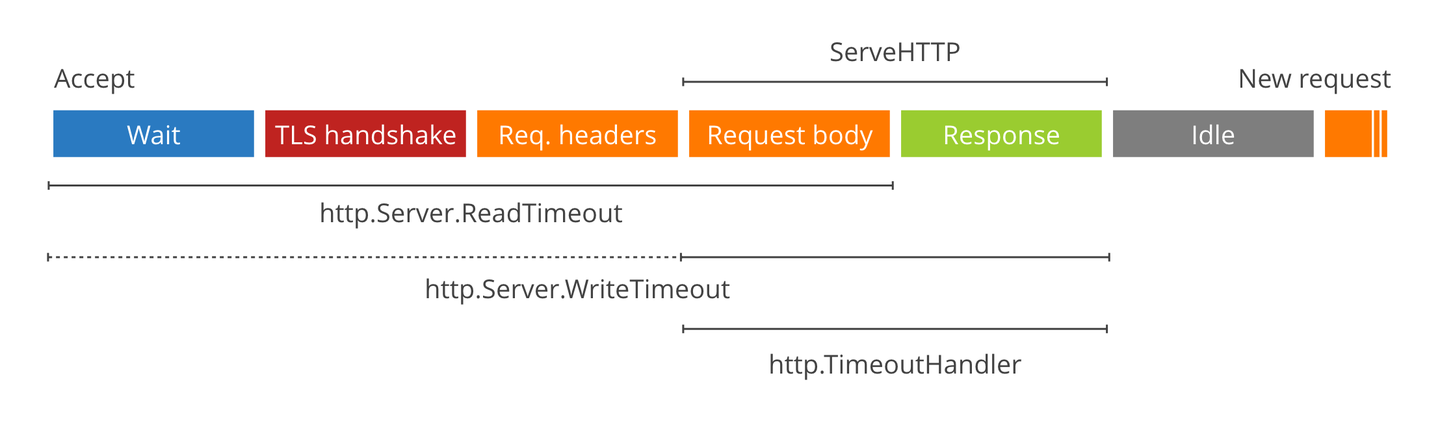
iflen(fieldDescriptions) != len(values) { err := errors.Errorf("number of field descriptions must equal number of values, got %d and %d", len(fieldDescriptions), len(values)) rows.fatal(err) return err } iflen(fieldDescriptions) != len(dest) { err := errors.Errorf("number of field descriptions must equal number of destinations, got %d and %d", len(fieldDescriptions), len(dest)) rows.fatal(err) return err }
if rows.scanPlans == nil { rows.scanPlans = make([]pgtype.ScanPlan, len(values)) for i := range dest { rows.scanPlans[i] = ci.PlanScan(fieldDescriptions[i].DataTypeOID, fieldDescriptions[i].Format, dest[i]) } }
for i, dst := range dest { if dst == nil { continue }
func(c *Conn)getCompositeFields(ctx context.Context, oid uint32)([]pgtype.CompositeCodecField, error) { var typrelid uint32
err := c.QueryRow(ctx, "select typrelid from pg_type where oid=$1", oid).Scan(&typrelid) if err != nil { returnnil, err }
var fields []pgtype.CompositeCodecField var fieldName string var fieldOID uint32 rows, _ := c.Query(ctx, `select attname, atttypid from pg_attribute where attrelid=$1 and not attisdropped and attnum > 0 order by attnum`, typrelid, ) // 这里是示例 _, err = ForEachRow(rows, []any{&fieldName, &fieldOID}, func()error { dt, ok := c.TypeMap().TypeForOID(fieldOID) if !ok { return fmt.Errorf("unknown composite type field OID: %v", fieldOID) } fields = append(fields, pgtype.CompositeCodecField{Name: fieldName, Type: dt}) returnnil }) if err != nil { returnnil, err }
return fields, nil }
后记
对于一个不熟悉的底层库,最好的学习方式还是看它的示例代码,库的开发者很难知道用户会踩哪些坑,文档中自然不会有,毕竟当局者迷。只从文档出发,很容易陷进未知的坑里,甚至掉坑里都不知道,业务出问题后,花费大代价排查之后,才知道掉坑里了。陌生的开源库在使用的时候还是先全库 clone 下来,用 api 的时候,就去源码里搜一下,看看开发者写的示例(不管是测试,还是其他地方的调用),当然现在也可以让 AI 先写,人只要再核实一下文档和源码,能节省很多学习的功夫。
[profiles.minimax-m2.5-free] model_provider = "openrouter" model = "minimax/minimax-m2.5:free"
如果是 Codex App,启动时可能还需要选择 API Key 登录,输入创建的 OPENROUTER_API_KEY。
Pi 接入,先安装 npm install -g @mariozechner/pi-coding-agent --registry https://registry.npmmirror.com,启动后输入 /login -> Use an API key -> OpenRouter -> [输入apikey] Pi 启动时可能报错 Failed to download fd: The operation was aborted due to timeout 或者 Failed to download fd: fetch failed,可以使用 brew install fd 安装 fd。
# 等待服务就绪 echo" Waiting for services..." for port in 8081 8082; do for i in $(seq 1 60); do if curl -sf http://127.0.0.1:${port}/health > /dev/null 2>&1; then echo" Port ${port} ready" break fi sleep 1 done done
# 启动 nginx 反向代理(前台运行) echo" Starting nginx on :11216" echo"" echo"=== Endpoints ===" echo" Embedding: POST http://localhost:11216/v1/embeddings" echo" Rerank: POST http://localhost:11216/v1/rerank" echo" Models: GET http://localhost:11216/v1/models" echo" Health: GET http://localhost:11216/health" echo""
defrun_applescript(script): """运行 AppleScript 脚本""" subprocess.run(["osascript", "-e", script]) defxls_to_xlsx(file_path="./xxx.xls"): """使用 AppleScript 修改 Excel 文件元数据""" applescript = f''' tell application "Microsoft Excel" -- 打开 .xls 文件 set inputFile to "{file_path}" -- 修改为你的文件路径 open inputFile -- 获取当前工作簿 set wb to active workbook -- 定义输出文件路径 set outputFile to "{file_path}x" -- 修改为你想保存的文件路径 -- 保存为 .xlsx 格式 save workbook as wb filename outputFile file format Excel XML file format -- 关闭工作簿 close wb saving no end tell ''' run_applescript(applescript)
defxlsx_to_xls(file_path="./xxx_tmp.xlsx"): """使用 AppleScript 修改 Excel 文件元数据""" applescript = f''' tell application "Microsoft Excel" -- 打开 .xls 文件 set inputFile to "{file_path}" -- 修改为你的文件路径 open inputFile -- 获取当前工作簿 set wb to active workbook -- 定义输出文件路径 set xlsFilePath to (inputFile as text) set xlsFilePath to text 1 thru -6 of xlsFilePath -- 去掉 ".xlsx" set xlsFilePath to xlsFilePath & ".xls" # log xlsFilePath -- 保存为 .xls 格式 save wb in xlsFilePath # save workbook as wb filename xlsFilePath file format Excel98to2004 file format with overwrite -- 关闭工作簿 close wb saving yes end tell ''' run_applescript(applescript)
defswrr_n(rs_arr, weight_total, schedule_num): ms = [(rs["ew"] / float(weight_total)) * (schedule_num-1) for rs in rs_arr] mzs = [int(m) for m in ms] mxs = [(i, m-int(m)) for i, m inenumerate(ms)] mxs = sorted(mxs, key=lambda x:x[1], reverse=True) for i, rs inenumerate(rs_arr): rs["cw"] = schedule_num * rs["ew"] rs["cw"] -= mzs[i] * weight_total
d = (schedule_num-1) - sum(mzs) for i inrange(d): rs_arr[mxs[i][0]]["cw"] -= weight_total