前言
最近业务调用方反馈接收到服务连接中断的错误(python requests 请求抛出异常 raise ConnectionError(err, request=request) \n ConnectionError: ('Connection aborted.', BadStatusLine("''",))),但从 golang 服务日志中看,服务应该是正常处理完成并返回了,且抛出异常的时间也基本和服务返回数据的时间一致,即表明在服务响应返回数据的那一刻,请求方同时抛出异常。
这个问题很奇怪,起初拿到一个 case 还无法稳定复现,最初怀疑是网络抖动问题,但后续一直会偶发性出现,直到拿到了一个能稳定复现的 case,深入跟踪排查后才发现与网络问题无关,是服务端框架应用设置不合理的问题。
问题篇
从网上搜索 python ConnectionError: ('Connection aborted.'),错误种类非常多,有网络问题,服务端问题(关闭连接,拒绝服务,响应错误等),客户端关闭连接,超时设置不合理,请求参数/协议错误等等,但若带上 BadStatusLine("''",) ,错误就相对比较明确了(BadStatusLine Error in using Python, Requests,Python Requests getting ('Connection aborted.', BadStatusLine("''",)) error),主要是由于收到了一个空响应(header/body),空响应可以明确是服务端返回的问题,一般可能有以下几个原因:1. 服务端反爬;2. 服务端超时(比如 nginx 默认 60s 超时);3. 网络错误。
由于是内部服务,所以反爬策略是没有的,而反馈的 case 都带有明显的特征(请求数据量大,处理耗时长),没有网络抖动那种随机性,所以应该也不是网络问题,剩下的只能是超时问题,由于业务方在前置策略上已经识别该 case 数据量大,所以不经过 nginx 网关,直连服务请求,所以也不会有 nginx 超时问题,只能是服务端自己超时。于是直接在代码中查找 timeout 关键字,发现在服务启动时设置了 ReadTimeout 和 WriteTimeout,进一步深挖之后,才对 go 服务的超时有了浅显的认识。
超时篇
参考资料:1. 你真的了解 timeout 吗?,2. i/o timeout , 希望你不要踩到这个net/http包的坑,3. net/http完全超时手册。
由于 HTTP 协议规范并未提及超时标准,而为保证服务稳定性,一般的 HTTP 服务请求都会设置超时时间,各 HTTP 服务端/客户端对于超时的理解大同小异,而这次的问题又起源与 go 服务,所以以 go 为例,分析一下超时。
客户端超时
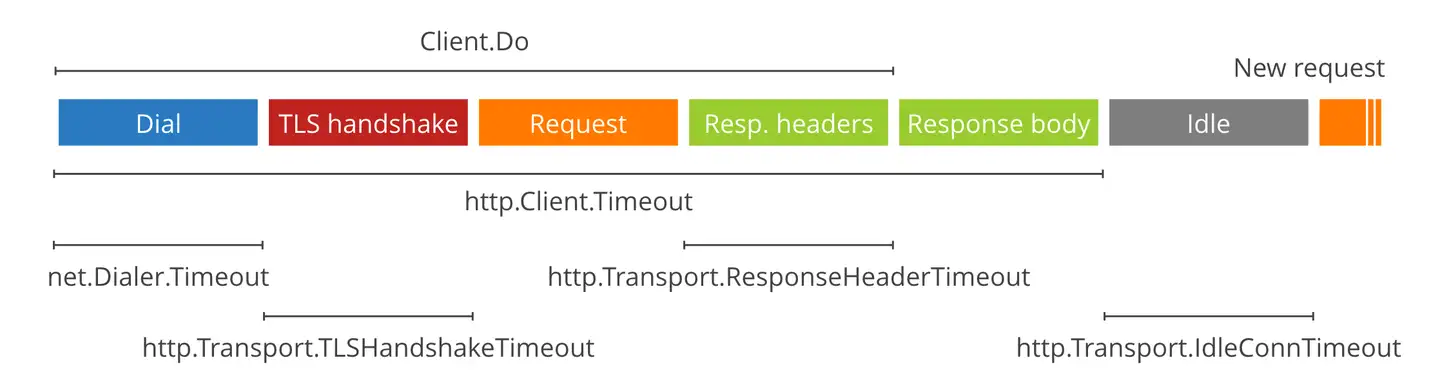
客户端超时,即 GET/POST 请求超时,这个很好理解,就是客户端发送请求到客户端接收到服务器返回数据的时间,算是开发的一般性常识,控制参数一般也特别简单,就是一个 timeout,当然 go 服务客户端支持设置更精细化的超时时间,一般也没啥必要。当客户端感知到超时时,会正常发起 TCP 断开连接的“四次挥手”过程。
服务端超时
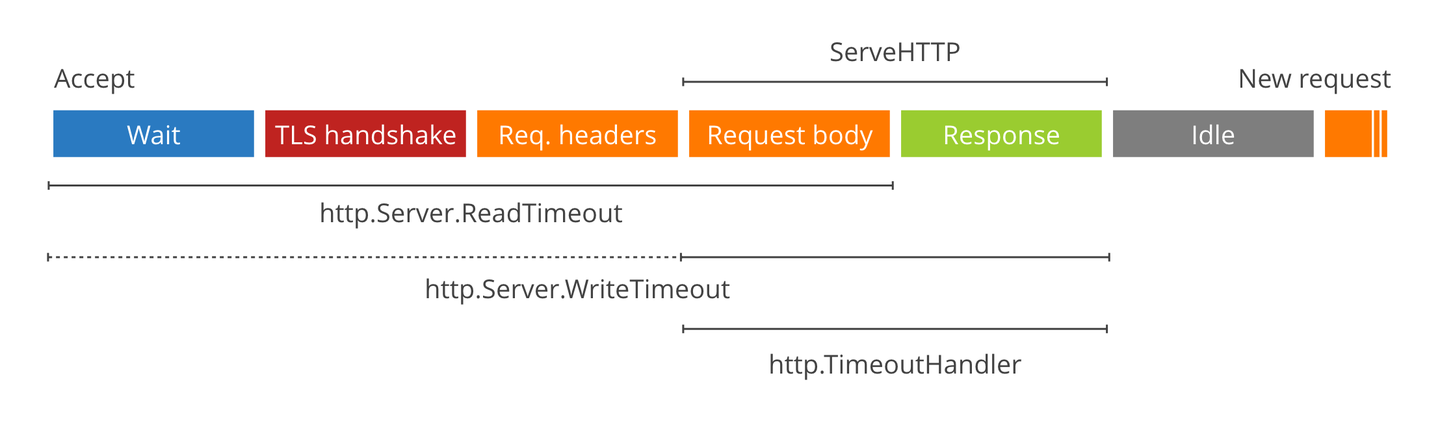
服务端超时,这才是引发问题的根本原因,go 服务端的超时,主要有两个参数,ReadTimeout 和 WriteTimeout,从上图可以看出,ReadTimeout 主要是设置服务端接收请求到读取客户端请求数据的时间(读请求的时间),WriteTimeout 是服务端处理请求数据以及返回数据的时间(写响应的时间)。GoFrame 框架的 ReadTimeout 默认值是 60s,在请求数据正常的情况下 ReadTimeout 也不可能超时,这次的问题主要出在 WriteTimeout,GoFrame 的默认值是 0s,代表不控制超时,但之前的开发者也同样设置为了 60s,导致服务端在处理大量数据时,发生了超时现象。
更深挖之后,才发现 WriteTimeout 的诡异之处,当 WriteTimeout 发生之后,服务端不会即时返回超时消息,而是需要等服务端真正处理完之后,返回数据时,才会返回一个空数据,即使服务端正常写入返回数据,但都会强制为空数据返回,导致请求客户端报错。这种表现,看起来就像是 WriteTimeout 不仅没有起到应有的作用,在错误设置的情况下,还会起到反作用,使服务响应错误。WriteTimeout 无法即时生效的问题,也同样有其他人反馈了:1. Diving into Go's HTTP server timeouts;2. net/http: Request context is not canceled when Server.WriteTimeout is reached。可能是网上反馈的人多了,go 官方推出了一个 TimeoutHandler,通过这个设置服务端超时,即可即时返回超时消息。仿照官方的 TimeoutHandler ,即可在 GoFrame 框架中也实现自己的超时中间件。
至于 WriteTimeout 为啥不起作用,个人猜测主要原因在于 go 服务每接收到一个请求,都是另开一个协程进行处理,而 goroutine 无法被强制 kill,只能自己退出,通常是要等到 goroutine 正常处理完之后才能返回数据,WriteTimeout 只是先强制写一个空数据占位,返回还是得等 goroutine 正常处理完。
所以正常的 go 服务,在使用类似于 TimeoutHandler 中间件的时候,也最好让 goroutine 尽可能快的退出,一种简单的方法是:1. 设置请求的 context 为 context.WithTimeout;2. 分步处理数据,每一步开始前都先检查请求传入的 context 是否已经超时;3. 若已经超时,则直接 return,不进行下一步处理,快速退出 goroutine。
后记
这次问题排查,碰到的最大障碍在于,前几次反馈的 case 难以复现,客户端请求报错和服务器返回的时间一致也不会让人往超时的角度去想,在拿到一个能稳定复现的 case 之后,才死马当活马医,先调一下超时参数试试。
关于 go 服务超时的文章,其实之前也看过,但没碰到具体问题,名词也就仅仅只是名词,很难理解背后的含义和其中的坑点,实践才能出真知 ╮(~▽~)╭。
附录
长连接超时
关于超时问题,也曾看到过有人碰到一个长链接服务的问题,现象是这样的:后端服务宕机之后,客户端可能需要很久才会感知到,原因在于 tcp 的超时重传机制,在 linux 中,默认会重传 tcp_retries2=15 次(即 16 次才会断开连接),而 TCP 最大超时时间为 TCP_RTO_MAX=2min,最小超时时间为 TCP_RTO_MIN=200ms。即在 linux 中,一个典型的 TCP 超时重传表现为:
| 重传次数 | 发送时间 | 超时时间 |
|---|---|---|
| -1(原始数据发送) | 0s | 0.2s |
| 0 (第 0 次重传) | 0.2s | 0.2s |
| 1 | 0.4s | 0.4s |
| 2 | 0.8s | 0.8s |
| 3 | 1.6s | 1.6s |
| 4 | 3.2s | 3.2s |
| 5 | 6.4s | 6.4s |
| 6 | 12.8s | 12.8s |
| 7 | 25.6s | 25.6s |
| 8 | 51.2s | 51.2s |
| 9 | 102.4s | 102.4s |
| 10 | 204.8s | 120s |
| 11 | 324.8s | 120s |
| 12 | 444.8s | 120s |
| 13 | 564.8s | 120s |
| 14 | 684.8s | 120s |
| 15 | 804.8s | 120s |
| 断开连接 | 924.8s(≈15min) |
所以客户端需要在 15 分钟之后才能感知到服务端不可用,如此,仅靠 TCP 自身的超时机制,很难发现服务端是否宕机/不可用,长链接不释放,进而可能导致客户端不可用且无感知,所以在长链接服务中,需要有其他的手段来保障服务稳定/可用性(eg:心跳探活)。
服务端 context canceled
Refer to: context canceled,谁是罪魁祸首
从官方的 net/http 包中可以知道,go 服务在接收请求时,会同时生成一个协程监控连接状态,当发现连接有问题(eg:客户端设置请求超时主动断开)时,会将该请求对应的 context cancel 掉,这时服务端如果再继续使用该 context 时,就会报错「context canceled」。当然,如果服务端发生错误,也同样会导致请求对应的 context cancel 掉。
服务端主动 cancel context 的好处在于可以快速释放资源,避免无效的请求继续执行(当然也得业务代码上主动去感知 context 是否 cancel,从而及时退出);坏处在于,如果服务端需要上报这个请求发生的错误(一般在后置中间件中进行错误上报),这个时候上报错误的请求需要另外生成一个新的 context,绝不能直接使用现有的 context,因为已有的这个 context 已经 cancel 掉了,继续使用会导致上报错误的请求发送失败,达不到上报的目的。